數位專欄

韓怡真
韓怡真為哈瑪星科技資深副總經理,主要負責公司產品研發及市場發展策略規劃,擔任軟協AI大數據智慧應用促進會副會長,協助推廣人工智慧大數據應用,協助產業AI化及AI產業化政策,啟動AI思維、觸動數位轉型。
哈瑪星科技,成立於2000年、員工人數180人
以人為本,發展資訊科技服務,致力於將系統模組化,主要產品與服務為網站共構、企業入口網,電子表單簽核、碳盤查及ESGP企業永續治理平台。提供客製化系統開發整合服務及運用模組化設計,快速協助客戶進行數位轉型。
生成式人工智慧(AI)熱潮襲捲全球,帶來了創新的衝擊。打破了我們取得資料的方式,讓資訊取得成本大幅下降,提升工作效率、創造力和便利性。個人及企業在此新技術的引領下,資料搜尋分析整理,將由自行彙整推斷結論,未來透過生成式AI,將更快速取得結論並產生新的洞察。
然而,隨著AI技術的快速演進,也浮現了相對應的風險和挑戰,特別是在數據隱私保護、資訊安全、誤導性訊息和道德考量等方面。政府和企業必須謹慎應對開發的危機與限制,以確保生成式AI的發展在為人類帶來福祉的同時,不會對社會和個人造成潛在的傷害。
受限現行大型語言模型訓練資料來源的限制,引用資料錯誤率高,導致回覆不夠精確;GPT-4最高僅提供32,768 Token數量限制,可以分析與回答的數據內容不充足;不同業務對資料、創意與穩定性的需求不同,單一問答方式無法滿足對外客戶服務及對內營運分析需求;使用者不知道如何問出好問題來滿足需求及可能不小心機密外洩,使其應用效益受到限制。
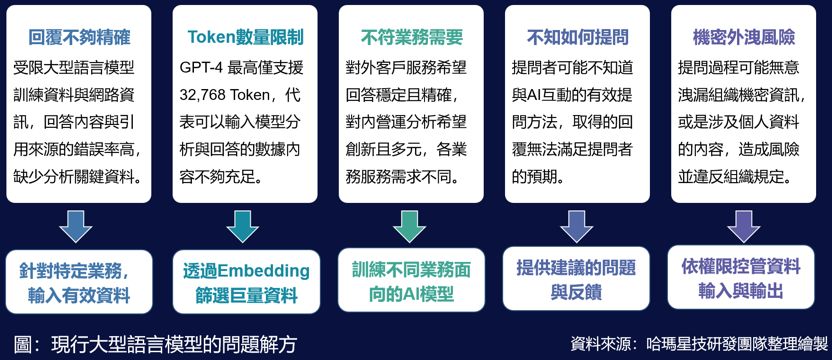
透過增加特定領域業務服務資料輸入,Embedding技術篩選巨量資料,解決數據內容不足及回覆不精確的問題。將應用在不同專業領域AI模型分開訓練,提升回答穩定精確度,來滿足各業務面需求。要能透過LLM得到符合需求回答,使用者必需學習有效的提問技巧,以優化模型識別使用者意圖,這對一般使用者不是一件容易的事。
在專業知識方面,AI大型語言模型不僅可以查找政府施政方針,還可以應用於不同專業領域,從醫療到法律、科學到工程、金融理財、ESG相關領域知識..等等,幫助人們快速進行資料收集、搜尋、整理、分析及給予結論建議,24小時提供服務,從而減輕人們尋求資訊查找答案的負擔,節省時間和資源。
AI大型語言模型正為政府和企業服務領域帶來革命性的變革,涵蓋了多種可應用的情境,將帶來前所未有的效益。在政府公共服務支援方面,AI大型語言模型能夠提供政府政策和法規的解釋,回答常見問題,甚至提供公共健康指導等服務。這不僅可以減輕政府人員的工作負擔,還能夠提供更迅速和準確的回答,提升公眾對政府服務的滿意度。
目前生成式AI在各領域應用仍在實驗中,也常見文不對題的答案,只要善用它,可以為個人及企業創造新價值,是一個稱職小幫手,也是數位轉型最佳利器。
(本篇文章轉載於財訊專欄)